Moore’s law states, that every two years, the number of transistors used in computer chips doubles. In this blog post, we’ll have some fun fitting a logistic growth function to the increase in transistor count in computers over time to see if Moore’s law comes to a halt or if that is a myth.
Optimization
Bayes
R Programming
Author
Damian Oswald
Published
May 5, 2024
Abstract
In this stimulating exploration, we delve into the future of Moore’s law by applying logistic growth modeling to transistor count data. Using both classical and Bayesian statistical techniques, we assess whether this cornerstone of technological advancement continues to hold true or is nearing its physical and theoretical limits. Join us as we unravel the intricate dance of innovation and natural constraints in the microchip industry.
What is Moore’s law, anyways?
In 1965, Gordon Moore observed that the number of transistors on a computer chip had increased exponentially over the past few years (1). Moore extrapolated that exponential growth and postulated that the number of transistors on a microchip would approximately double every two years.
This simple rule has become famous as Moore’s law. And it has been proven to be astonishingly right! For more than half a century, the increase in transistor number has been following Moore’s law, leading to more processing power, faster computation, and smaller devices (2). This exponential growth has been an essential ingredient in the development of modern technology.
However, some experts have begun to question if this trend can continue over the next decades, or if we’re approaching the limits of Moore’s law. After all, Moore’s law was always doomed to break down at some point or another. No exponential growth can continue indefinitely. If transistors are continuously shrunk, they’ll eventually reach the size of an atom. And as the physics professor turned youtuber Sabine Hossenfelder has jokingly stated in one of her videos: An atom is an atom, not a transistor (3).
In this blog post, we’ll look at some up-to-date data and fit a logistic function to the number of transistors in computers over time to potentially explore the future of Moore’s law.
Preparing the Data
For the following mini-project, we will work with data about the number of transistors for different processors – the sort of data you would need to look at Moore’s law. You can scrape it from the corresponding Wikipedia page with the following R code (4).
Code for scraping data from a Wikipedia table.
library(httr)library(XML)url <-"https://en.wikipedia.org/wiki/Transistor_count"data <-readHTMLTable(doc=content(GET(url), "text"),which =4,skip.rows =1,trim =TRUE)data <- data[-nrow(data),1:3]colnames(data) <-c("Processor", "Transistors", "Year")clean <-function(x){ x <-unlist(strsplit(x, split ="")) i <-1while (x[i] %in%c(as.character(0:10), ",")) { i <- i+1 } x <-paste0(x[1:(i-1)], collapse ="") x <-gsub(",","",x)return(as.numeric(x))}for (i in1:nrow(data)) { data[i,"Transistors"] <-clean(data[i,"Transistors"]) data[i,"Year"] <-clean(data[i,"Year"])}data$Processor <-gsub(" \\[.*?\\]", "", data$Processor)data$Processor <-gsub(" \\(.*?\\)", "", data$Processor)data <-na.omit(data)data <- data[-c(159,169),]
1
Packages needed for the scraping.
2
Scrape the data from Wikipedia using the readHTMLTable function from the XML package.
3
Remove the last three columns, as they are not necessary for this project.
4
Rename the three remaining columns.
5
This function reads everything as texts, hence the data needs some manipulation before we can work with it. We can do that by applying a cleaning function to the columns.
6
Remove any content within brackets or parentheses in the transistors name.
7
Further clean data by removing special cases due to Wikipedia’s special table formatting.
To speed things up, you may also download a cleaned version of the data directly from this website.
data <-read.csv("https://damianoswald.com/data/transistors.csv")
The data is structured very simply: Covering 236 processors between 1970 and 2023, we are provided with the processor name (Processor), the number of transistors on the computer chip (Transistors) and the year the processor was first built (Year).
Table 1: First five observations in the data frame.
Processor
Transistors
Year
MP944
74442
1970
Intel 4004
2250
1971
TMX 1795
3078
1971
Intel 8008
3500
1972
NEC μCOM-4
2500
1973
First look at the data
We’ll start by visualizing the observations in the downloaded data set. A simple scatter plot should give us a good Idea of what’s going on.
plot(Transistors ~ Year, data = data)
Running the above R code should result in a plot similar to figure 1. Every single point represents a processor. Seemingly, the number of transistors per computer chip completely exploded in recent years. It didn’t, though. This is simply what exponential growth looks like.
Figure 1: Scatterplot of the number of transistors per processor over time. Due to the exponential increase, a change can only be detected by eye from the early 2000s onwards.
Looking at specific processors, we may notice that with M2 Ultra, Apple has recently released a chip consisting of 134 billion transistors. However, due to the exponential growth, it is impossible to see what’s going on in the last millennium. Hence, data about exponential growth is commonly visualized with logarithmic axes.
plot(Transistors ~ Year, data, log ="y")
With the argument log = "y", we tell R to use a logarithmic axis on the y axis only. Alternatively, we could use the arguments x or xy – however, that would be undesirable in this context.
Figure 2: Scatterplot of the number of transistors per processor over time. By having a logarithmic y-axis, the constant exponential increase can be highlighted.
Now we get a much better overview of what was going on! If we produce a scatter plot with logarithmic y-axis, we get to see a seemingly linear growth of the number of transistors per computer chip (Figure 2).
Endless exponential growth
In a first step, we’ll fit an exponential growth curve to the transistor count data. The most straight-forward way to do this is using a linear regression model after transforming the transistor count.
The process of transforming one (or multiple) variables for a linear regression model is what is called a linearization. By applying the logarithmic function to an entire variable, we can produced a linear relationship. Such a linearization of the relationship via a logarithmic transformation has the additional benefit of scaling the error and thus helps avoiding heteroskedasticity (5, 6). If we log-transform the y variable, the errors are weighted relative to the magnitude of the observation. Thus, fitting a linear model on the transformed data is preferable over fitting a non-linear model to the original data.1
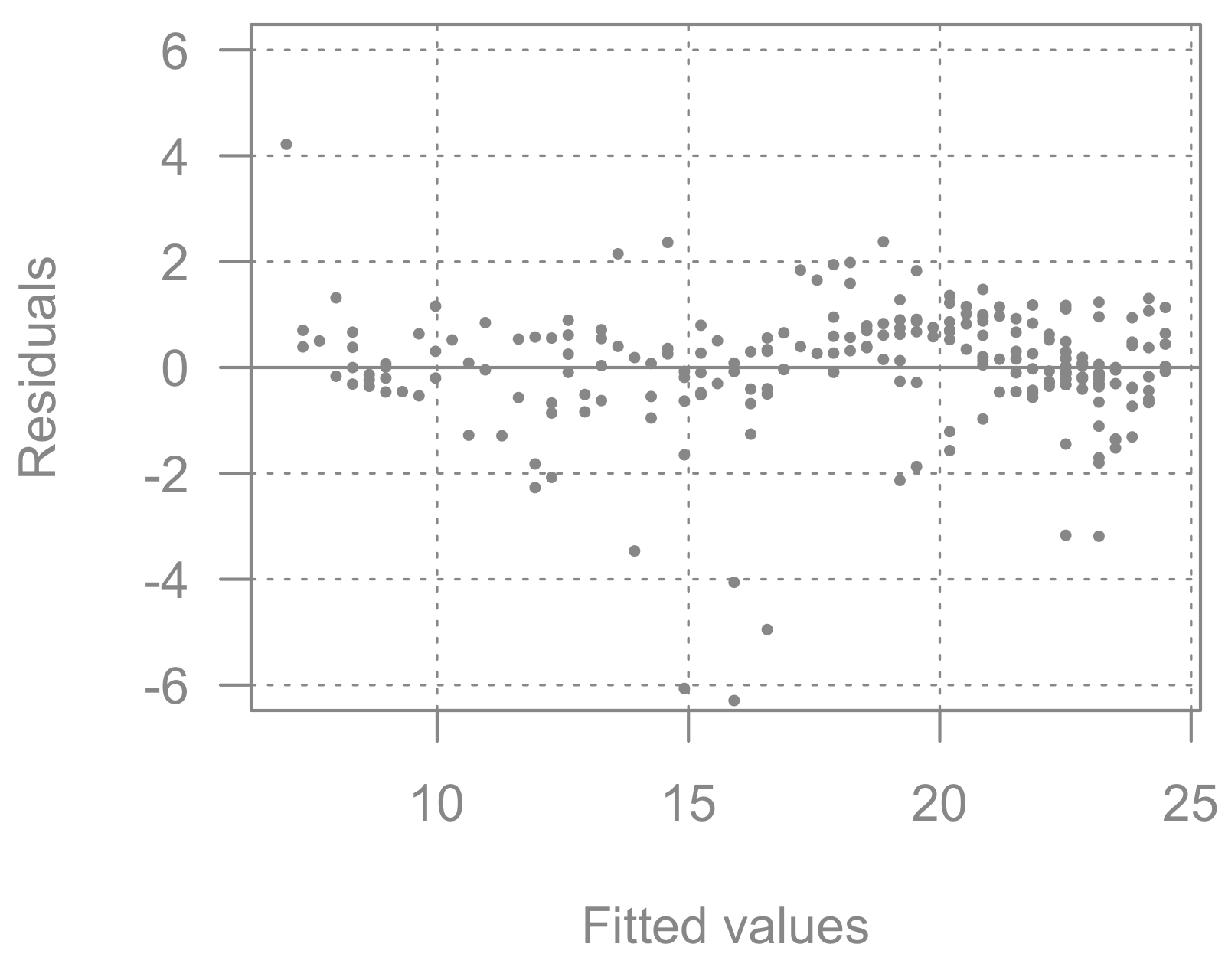
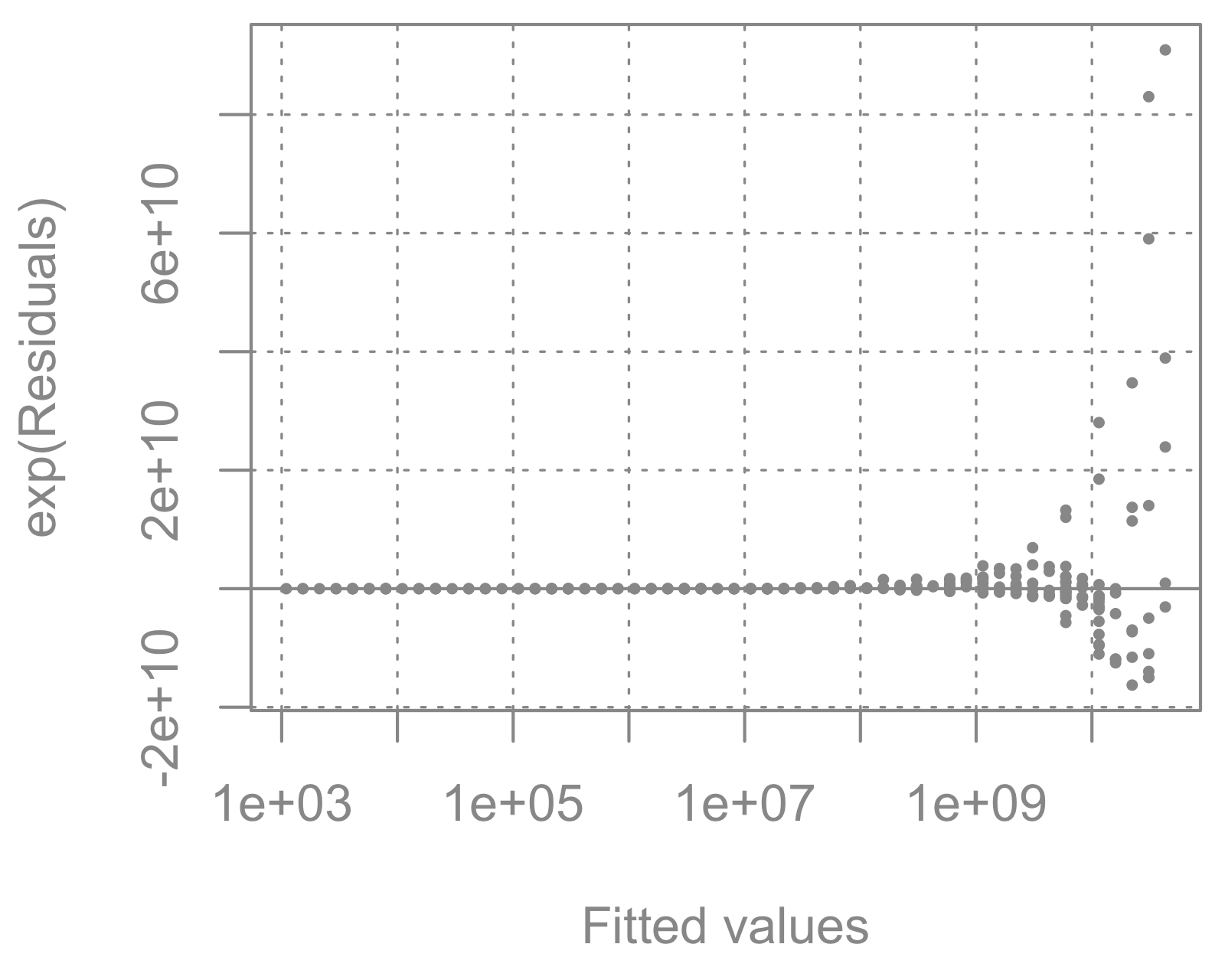
1 This problem becomes evident when looking at a Tukey-Anscombe plot of the model.
When we are modelling \log y, there is hardly any heteroskedasticity.
In comparison, the variance is not at all equal for the actual values of the residuals.
Fitting a linear model on linearized data is quite straight-forward in R:
model <-lm(log(Transistors) ~ Year, data = data)summary(model)
Note how we simply use log(Transistors) in the model to achieve the linearization. The coefficients of this linear model are displayed in table 2.
Table 2: Coefficients and corresponding t-test of the log-transformed linear model.
Estimate
Std. Error
t value
p value
\beta_0 (Intercept)
-642.97
10.335
-62.212
<10-16
\beta_1 (Year)
0.323
0.00516
63.980
<10-16
Figure 3 illustrates what this exponential growth model would look like both with standard as well as logarithmic y-axis. Note how the variance of the error of the model (which is assumed to be equal across samples for the linear model) is only equal on the right.
Figure 3: Number of transistors for different processors. The line represents the fit of a log-transformed linear model. Meanwhile, the grey shade indicates the area of one standard deviation around the linear fit (not the confidence interval).
Checking and applying Moore’s law
Now that we have the coefficient \beta_1 retrieved, we can calculate if Moore’s law holds is right for the data at hand. We can quickly calculate the predicted increase in the transistor count g within n years as:
g = e^{\beta_1 n} = \exp \left(0.33 \times 2 \right) = 1.934
\tag{1} The calculation says that – based on this specific model – the transistor count would increase by 1.934 within two years. That is indeed still astonishingly close to Moore’s law, which stated that the transistor count would double every two years.
We could also use the model to estimate in what year we will we have a (commercial) trillion transistor chip.
\ln y = \beta_0 + \beta_1 x \qquad
x = \frac{\ln y - \beta_0}{\beta_1} =
\frac{\ln 10^{12} + 643}{0.33} = 2032.5
\tag{2} According to the model prediction, that would be sometime during the summer of 2032. This seems somewhat realistic. After all, Intel announced a plan last year to build a trillion transistor chip until the year 2030 (7). Keep in mind, the model predicts the mean number of transistors per chip for various processors in a given year. Assuming Intel produces a chip roughly one standard deviation better than the mean at the time, they would easily achieve their goal if Moore’s law continues to hold true.
Is a exponential growth curve realistic?
As mentioned in the introduction, by sheer logic, Moore’s law has to break down at some point. There are physical limits on how small transistors can get. These physical limits might be reached some day. The big question there: When does that happen? We’ll try to dive into this question a little mor in the next part of this blog post.
Fitting a logistic growth curve
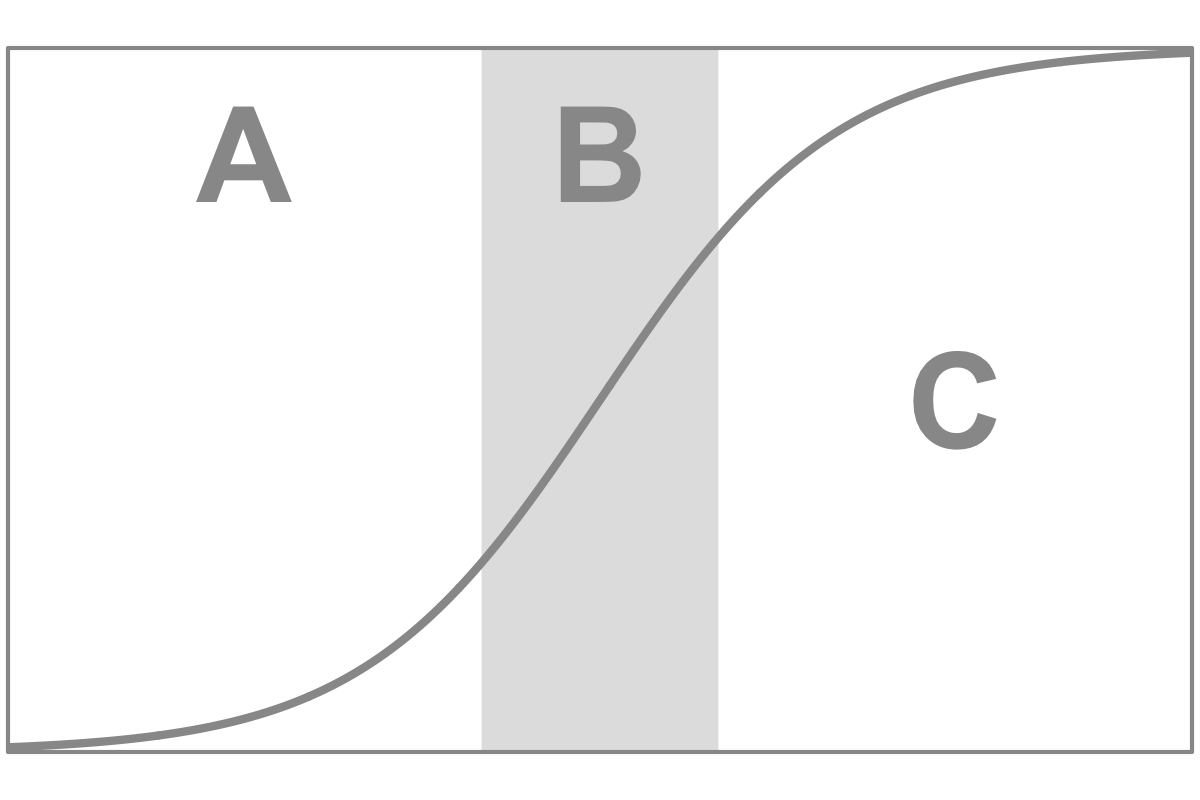
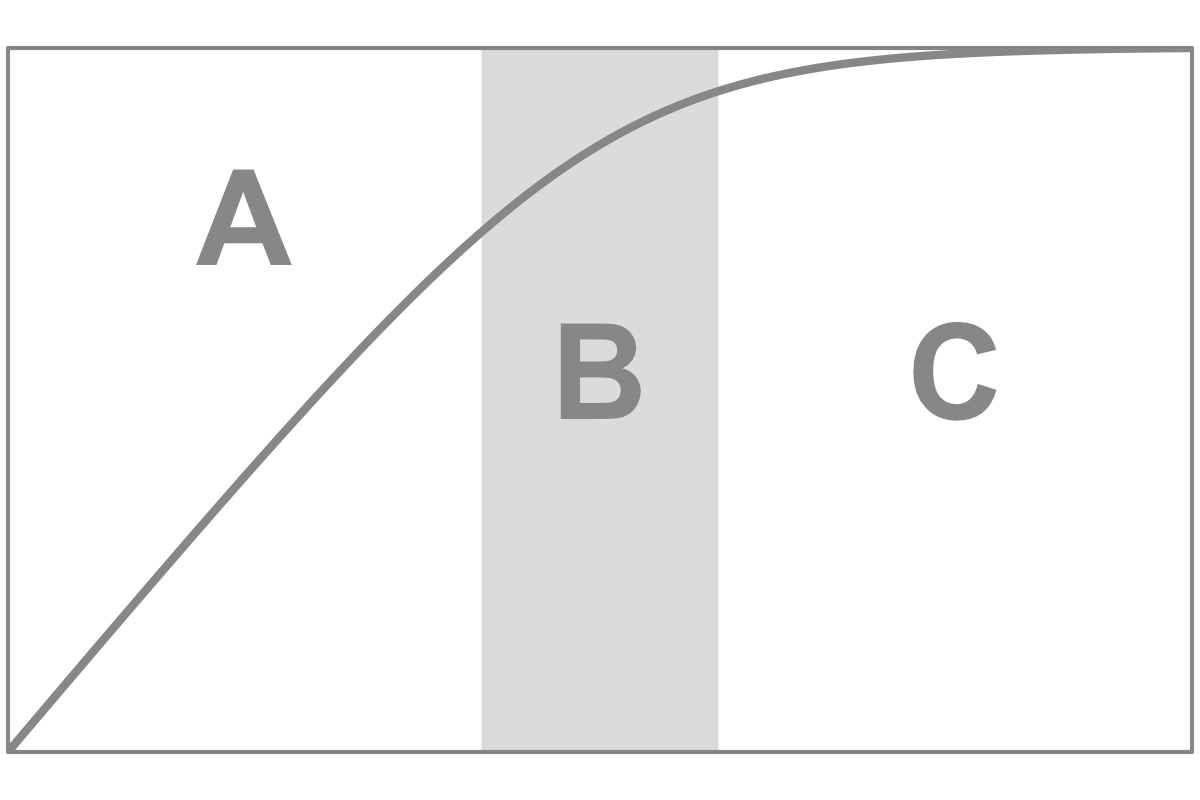
If we consider the inevitable breakdown of Moore’s law, we could switch the model used to a more appropriate one. For example, the logistic function is a valuable tool for examining the growth of a system that has a limited carrying capacity. Unlike exponential growth, which implies unbounded increase, a logistic function is characterized by an initial period of exponential growth, followed by a tapering off as the system approaches its carrying capacity. By fitting a logistic function to our data, we may gain insights into whether Moore’s law is coming to a halt, or at least what that would look like.2
2 The logistic growth curve may be characterized by three phases: At first (A), the function closely resembles exponential growth. In the second phase (B), it much more resembles linear increase. In the third phase (C) the system becomes saturated, the logistic growth function converges towards the carrying capacity.
If we display the same function with a logarithmic y-axis, it appears linear in the exponential phase, starts curving in the linear phase and converges to L in the saturation phase.
For the reasons explained before, we will stick to a logarithmic transformation of the model. Hence, we’ll express the logistic growth curve as follows:
f(x \mid L, k, x_0) = \ln \frac {L}{1+e^{-k(x-x_0)}}
\tag{3} where L, k and x_0 are the model’s parameters. Specifically, L is the carrying capacity of the system (that would be the maximum number of transistors per computer chip physically possible in our case), k is the logistic growth rate, and x_0 is the function’s inflection point.
Here’s how we can implement the logistic growth model as a function in R. Note that we are using a parameter vector theta instead of single arguments, this will make life easier later on.
f <-function(x, theta) {log(theta["L"]/(1+exp(-theta["k"] * (x-theta["x0"]))))}
Maximum likelihood estimation
The most straightforward way of finding the parameters of the logistic growth model is the maximum likelihood estimation (MLE). If we assume the model errors to be additive3, and Gaussian distributed, then minimizing the sum of squared residuals of the model will result in the maximum likelihood estimation.
3 Additivity of the errors refers to the following generic model structure: y = f(x) +\varepsilon On the other hand, a model with multiplicative errors would look differently: y = f(x) \times e^\varepsilon Essentially, the additive error model defines the error as the difference between measurement and prediction, while the multiplicative error model defines the error as the ratio between the two (8).
In order to estimate the parameters as detailed in equation 4, we can simply write the cost function J in R code and minimize it using the general-purpose optimization tool optim which is included in the R package stats. This program runs the Nelder-Mead downhill simplex algorithm by default in order to minimize any desired objective function (9).
Define the cost function J, which in this case is simply the sum of squared residuals of the model f.
2
Find the model parameters by minimizing the cost function J. Note that we need to pass an initial guess for the parameters in order for the optimization algorithm to work well.
This seemingly worked well: we get the following estimated parameter values: \hat L = 10^{12}, \hat x_0 = 2032.5, and \hat k = 0.33. However, the first parameter estimate looks suspicious – after all, the estimate \hat{L} exactly the same as our initial guess for L which we passed to the solver via the optim() function. Coincidence? I think not!
Indeed, if we were to pick another initial guess, say L = 10^{15}, the solver would find a solution of \hat{L} = 10^{15} – the other estimates, i.e. \hat x_0 and \hat k however, would change. To conclude, we have a dependency of the parameter estimation from the initial guess, which simply derives from the fact that we have no indication of whether there is a deceleration of the exponential growth yet or not.
Figure 4: Visualization of the fitted logistic growth function. The carrying capacity L, i.e. the upper bound of the logistic growth function, depends on the initial guess of that parameter. Note that the grey shade indicates the area of one standard deviation around the prediction.
To further investigate the relationship between the three parameters of our simple model, we could adopt a Bayesian model calibration scheme.
Bayesian estimation of the model parameters
To gain some more insight into the dependencies among the parameters of the logistic growth model, we’ll adopt a Bayesian estimation approach. This method not only allows us to incorporate prior beliefs about the parameters but also helps us understand the uncertainties and interdependencies of the model’s parameters.
In the Bayesian framework, we’ll express our prior knowledge and beliefs about the parameters through prior distributions. These priors are then updated with the data we have to form the posterior distributions, which give us an idea of the probability distribution of the parameters after considering the evidence. Specifically, we’ll use a sampling-importance-resampling (SIR) algorithm, which is a stochastic simulation technique used to approximate the posterior distributions of the model parameters.
n <-100000prior <-data.frame(L =10^runif(n, min =12, max =15),x0 =runif(n, min =2020, max =2100),k =runif(n, min =0.2, max =0.5))loglikelihood <-function(y, m) {sum(log((1/(sd(y)*sqrt(2*pi)))*exp(-0.5*((y-m)/sd(y))^2)))}logL <-numeric(n)for (i in1:n) { logL[i] <-loglikelihood(y =log(data$Transistors),m =f(data$Year, unlist(prior[i,1:3])))}L <-exp(logL)w <- L/sum(L)s <-sample(x =1:nrow(prior), size = n, replace =TRUE, prob = w)posterior <- prior[s, 1:3]
1
Generate a prior. Here, n triplets are sampled, each from a respective uniform distribution.
2
This function calculates the log-likelihood.
3
Compute the log-likelihood for every parameter triplet in the prior. The log-likelihood is preferred over the likelihood in this scenario, since it can be calculated as a large sum, which is much more numerically robust than a large product as in the case of the likelihood function.
4
Compute the likelihood L as \texttt L = e^{\texttt{logL}}.
5
Calculate the weights w from the likelihood L.
6
Generate the posterior by taking weighted samples from the prior using the calculated weights w.
One critical aspect of Bayesian estimation is the choice of prior distributions. These priors can massively influence the outcomes of the model, especially in cases where data is sparse or the model is highly sensitive to the parameter values. For instance, choosing a broad prior for the carrying capacity L allows us to explore a wide range of potential upper limits to the transistor count, from very pessimistic to highly optimistic scenarios. Similarly, k and x_0 require some consideration, as they determine the model’s flexibility.
Figure 5: Two-dimensional kernel density estimation of the posterior for the logistic model parameters, i.e. the carrying capacity L, the inflection point x_0, and the logistic growth rate k. It is very apparent that the carrying capacity and the inflection point are coupled.
By implementing this Bayesian approach, we not only obtain estimates for L, k, and x_0 but also capture the dependencies and uncertainties associated with these estimates (Figure 5). The resulting posterior distributions provide an insight how the logistic growth curve’s parameters are expected to be coupled: The higher the carrying capacity L, i.e. the maximally reachable number of transistors on a computer chip, the later the inflection point will be; and vice versa. Interestingly, the highest posterior density for the inflection point happens between 2030 and 2040, but this doesn’t seem to be a clear signal.
Finally, we may visualize the logistic growth model with the credibility interval (Figure 6). A credibility interval represents the range within which a parameter lies with a certain probability, based on the posterior distribution, reflecting direct probabilistic beliefs about the parameter itself, unlike a confidence interval which quantifies the variability of estimated parameters across hypothetical repeated sampling.
Figure 6: This plot showcases the estimated logistic growth curve of transistor counts, where the solid line represents the median prediction and the grey area indicates the 95% credibility interval, reflecting the range of plausible values based on the Bayesian model’s uncertainty.
The visualization primarily illustrates uncertainty: While it’s unclear whether the exponential growth in transistor counts will persist or falter in the coming decades, current trends show little indication of a slowdown.
No reason for pessimism
The future trajectory of Moore’s law remains a captivating mystery. However, observations of transistor counts on chips are often misleading, as they don’t represent the knowledge of what is technologically possible. Notably, Jim Keller, a seasoned chip designer, emphasizes that Moore’s law pivots not just on the size of transistors but critically on the design and arrangement of these transistors on the chip (10). More generally, high-performance electronics will focus on increasing the rate of computation rather than merely downsizing transistors (11).
The semiconductor industry today faces an extreme complexity in microchip design, which likely poses insurmountable challenges for smaller or even mid-sized companies. Consequently, the landscape is dominated by just a few giants – GlobalFoundries, Intel, Samsung, and TSMC – who continue to push the boundaries of what’s possible, while smaller entities focus on producing legacy chips for a variety of hardware applications.
Despite these complexities, there’s hardly any evidence to suggest that the exponential phase of growth in transistor counts is nearing its end. Moore’s law isn’t decelerating; instead, it’s evolving with the changing dynamics of chip design and manufacturing. Looking ahead, we can likely anticipate a continued surge in computational power into the next decade, especially considering the massive investments being made in preparation to the advent of artificial intelligence. The precise path of Moore’s law may be uncertain, but its influence on the march of technology is undeniably robust.
@online{oswald2024,
author = {Oswald, Damian},
title = {Is {Moore’s} Law Slowing down?\textbackslash n},
date = {2024-05-05},
url = {damianoswald.com/blog/moores-law},
langid = {en},
abstract = {In this stimulating exploration, we delve into the future
of Moore’s law by applying logistic growth modeling to transistor
count data. Using both classical and Bayesian statistical
techniques, we assess whether this cornerstone of technological
advancement continues to hold true or is nearing its physical and
theoretical limits. Join us as we unravel the intricate dance of
innovation and natural constraints in the microchip industry.}
}